Начало работы с озерами данных
Практическое руководство по выполнению запросов к таблицам озера данных, ускорению их с помощью MergeTree и записи результатов обратно в Iceberg. Во всех шагах используются общедоступные наборы данных; они работают как в Cloud, так и в OSS.
Скриншоты в этом руководстве взяты из SQL-консоли ClickHouse Cloud. Все запросы работают как в Cloud, так и в самоуправляемых развертываниях.
Прямые запросы к данным Iceberg
Самый быстрый способ начать работу — использовать табличную функцию icebergS3(): укажите на таблицу Iceberg в S3 и сразу выполняйте запросы — никакой предварительной настройки не требуется.
Изучите схему:
Выполните запрос:
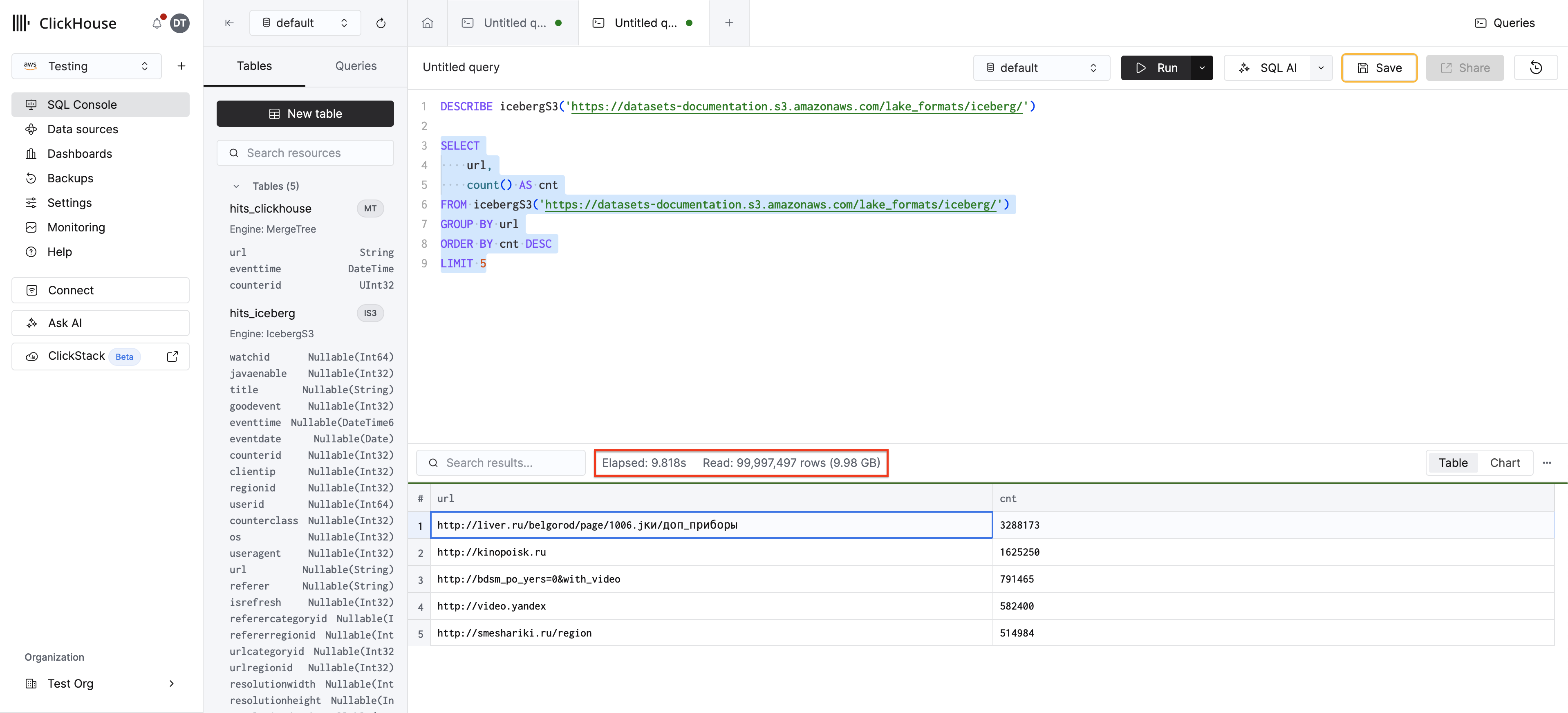
ClickHouse считывает метаданные Iceberg напрямую из S3 и автоматически определяет схему. Тот же подход применим для deltaLake(), hudi() и paimon().
Подробнее: Прямые запросы к открытым табличным форматам — описание всех четырёх форматов, кластерных вариантов для распределённого чтения и параметров серверной части хранилища (S3, Azure, HDFS, локальное).
Создание постоянного табличного движка
Для многократного доступа создайте таблицу с использованием движка таблиц Iceberg, чтобы не указывать путь каждый раз. Данные остаются в S3 — никакого дублирования данных не происходит:
Теперь выполните запрос к ней, как к любой таблице ClickHouse:
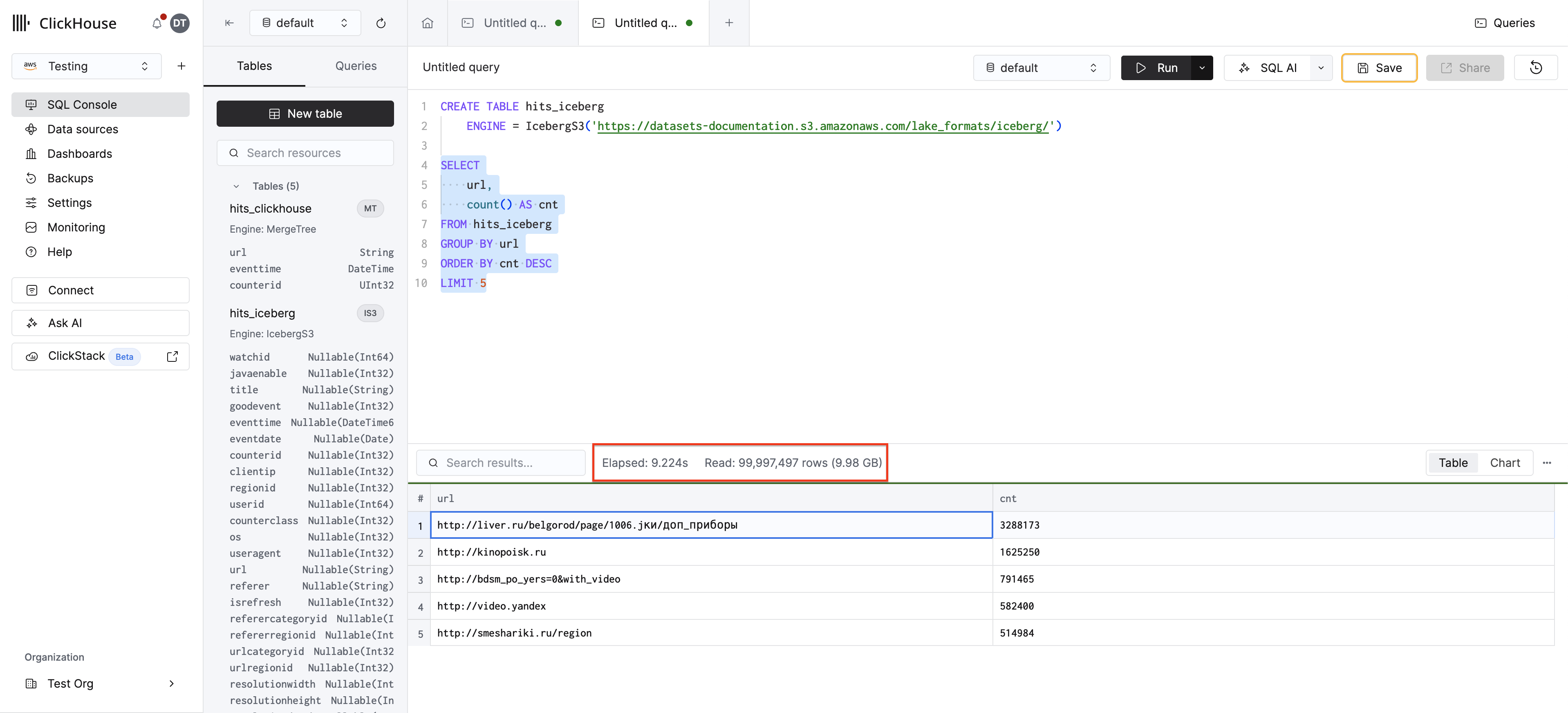
Движок таблиц поддерживает кэширование данных, кэширование метаданных, эволюцию схемы и перемещение во времени. Подробнее о возможностях движка таблиц см. в руководстве Прямые запросы, а полное сравнение функций — в матрице поддержки.
Подключение к каталогу
Большинство организаций управляют таблицами Iceberg через каталог данных для централизации метаданных таблиц и упрощения их обнаружения. ClickHouse поддерживает подключение к каталогу с помощью движка базы данных DataLakeCatalog, предоставляя все таблицы каталога как базу данных ClickHouse. Это более масштабируемый подход: по мере создания новых таблиц Iceberg они автоматически становятся доступны в ClickHouse без каких-либо дополнительных действий.
Ниже приведён пример подключения к AWS Glue:
Каждый тип каталога требует собственных настроек подключения — полный список поддерживаемых каталогов и их параметров конфигурации см. в руководствах по каталогам.
Просматривайте таблицы и выполняйте запросы:
Обратные кавычки вокруг <database>.<table> обязательны, поскольку ClickHouse не поддерживает более одного пространства имён нативно.
Подробнее: Подключение к каталогу данных — полное руководство по настройке Unity Catalog с примерами для Delta и Iceberg.
Выполнение запроса
Независимо от того, какой метод вы использовали выше — табличная функция, движок таблиц или каталог — один и тот же ClickHouse SQL работает во всех случаях:
Синтаксис запроса идентичен — изменяется только секция FROM. Все функции SQL ClickHouse, объединения и агрегации работают одинаково вне зависимости от источника данных.
Загрузка подмножества данных в ClickHouse
Выполнение запросов к Iceberg напрямую удобно, однако производительность ограничена пропускной способностью сети и структурой файлов. Для аналитических нагрузок загружайте данные в нативную таблицу MergeTree.
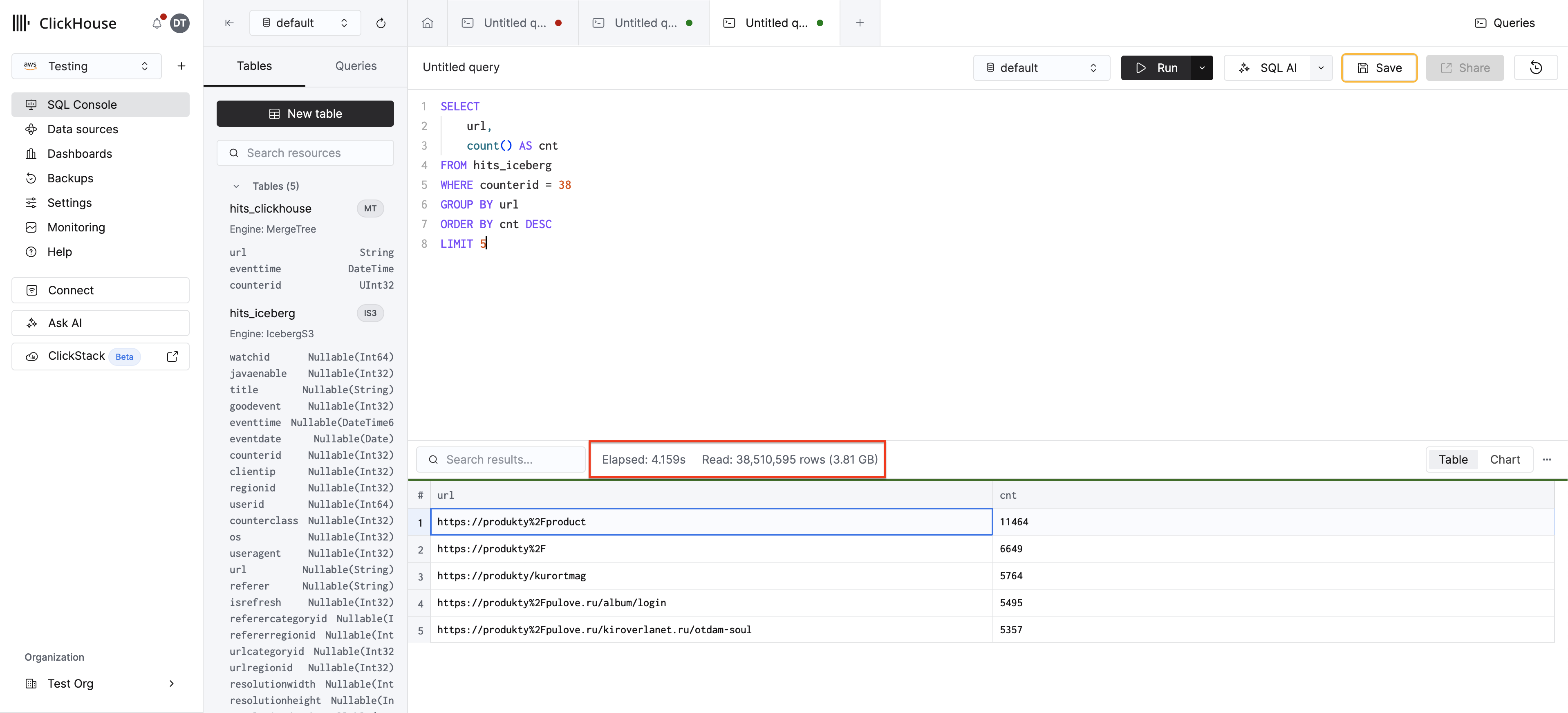
Сначала выполните отфильтрованный запрос к таблице Iceberg, чтобы получить базовые показатели:
Этот запрос сканирует весь набор данных в S3, поскольку Iceberg не учитывает фильтр counterid — выполнение может занять несколько секунд.
Теперь создайте таблицу MergeTree и загрузите данные:
Повторно выполните тот же запрос к таблице MergeTree:
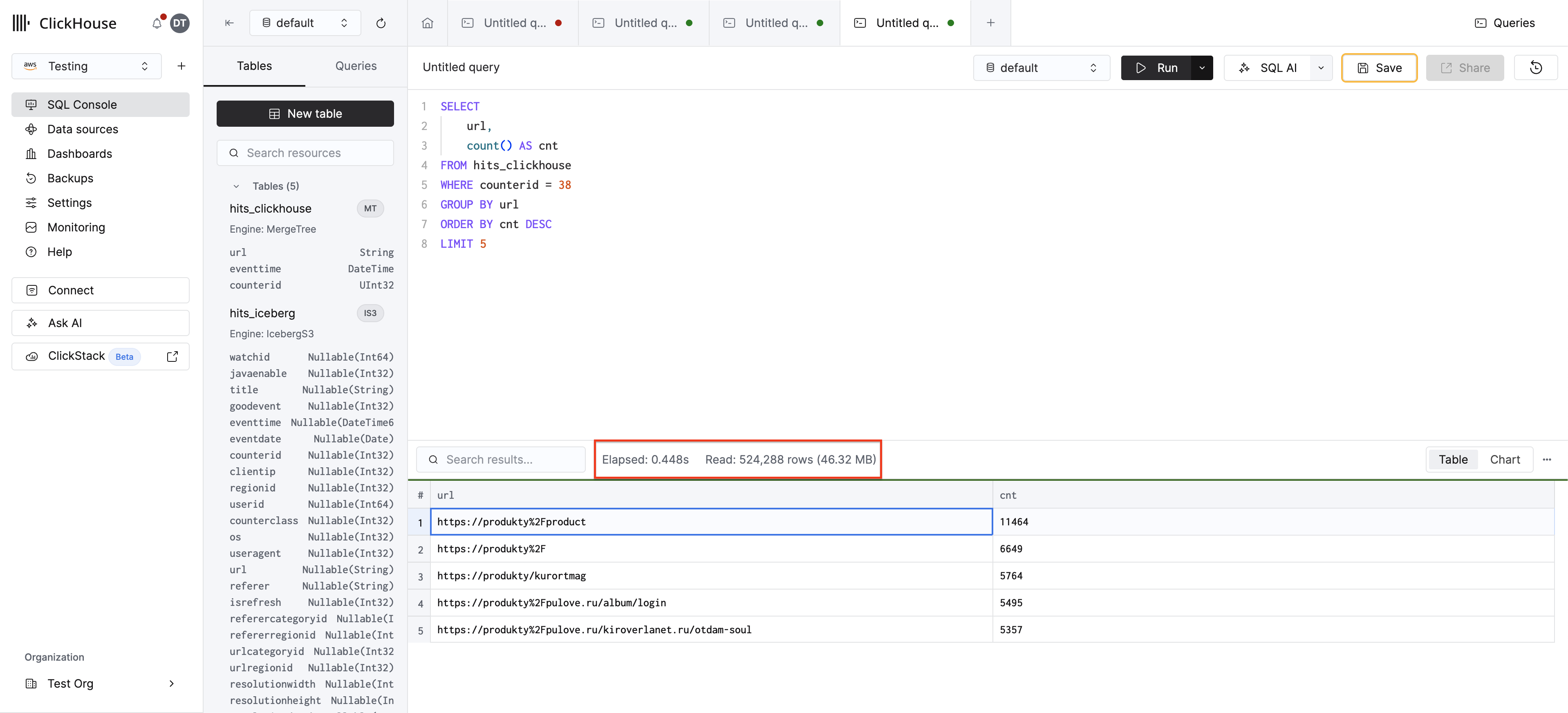
Поскольку counterid является первым столбцом в ключе ORDER BY, разреженный первичный индекс ClickHouse переходит непосредственно к нужным гранулам — считывая только строки, где counterid = 38, вместо сканирования всех 100 миллионов строк. Это обеспечивает значительное ускорение.
Руководство по ускорению аналитики развивает эту тему, рассматривая типы LowCardinality, полнотекстовые индексы и оптимизированные ключи сортировки, и демонстрирует ~40-кратное ускорение на наборе данных из 283 миллионов строк.
Подробнее: Ускорение аналитики с MergeTree — оптимизация схемы, полнотекстовое индексирование и полное сравнение производительности до и после.
Запись данных обратно в Iceberg
ClickHouse также может записывать данные обратно в таблицы Iceberg, обеспечивая обратные ETL-процессы — публикацию агрегированных результатов или подмножеств данных для использования другими инструментами (Spark, Trino, DuckDB и др.).
Создайте таблицу Iceberg для вывода данных:
Запись агрегированных результатов:
Полученная таблица Iceberg доступна для чтения в любом совместимом с Iceberg движке.
Подробнее: Запись данных в открытые табличные форматы — запись необработанных данных и агрегированных результатов на основе набора данных UK Price Paid, включая вопросы проектирования схемы при сопоставлении типов ClickHouse с форматом Iceberg.
Следующие шаги
Теперь, когда вы увидели весь процесс целиком, изучите подробнее каждое направление:
- Выполнение запросов напрямую — Все четыре формата, варианты кластеров, Движки таблиц, кэширование
- Подключение к каталогам — Полное руководство по Unity Catalog с Delta и Iceberg
- Ускорение аналитики — Оптимизация схемы, индексирование, демонстрация ускорения примерно в 40 раз
- Запись в озера данных — Запись сырых данных, агрегированная запись, сопоставление типов
- Матрица поддержки — Сравнение возможностей в разных форматах и бэкендах хранения
